
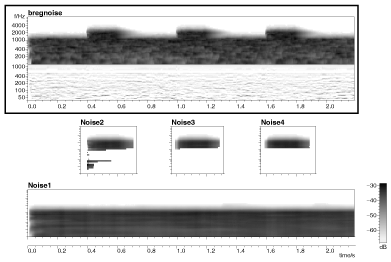
This sound is the artificial alternation of low-band and broad-band noise used as an example of the `old-plus-new' organizing principle. The sound examples illustrating the system's organization into a continuous low-band of noise with additional high-frequency bursts, are:
 1.1 The original sound (2.2 seconds)
1.2 The noise cloud comprising the continuous low-frequency noise
1.3 The remaining noise clouds for the higher-frequency energy, merged into a single soundfile
1.4 All the system-generated noise clouds summed together to reproduce the input.
1.1 The original sound (2.2 seconds)
1.2 The noise cloud comprising the continuous low-frequency noise
1.3 The remaining noise clouds for the higher-frequency energy, merged into a single soundfile
1.4 All the system-generated noise clouds summed together to reproduce the input.
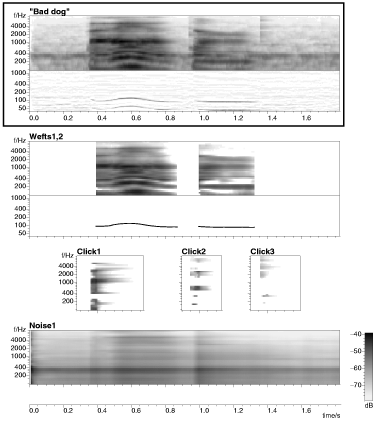
The second sound example is a male speaker saying "bad dog" against a quiet but audible background of fan noise. The sound examples, illustrated in figure 5.7 (above), are:
2.1 The original sound (1.8 seconds)
2.2 The background noise cloud ("Noise1" in the figure)
2.3 The two wefts comprising the voiced speech ("Wefts1,2")
2.4 The three click elements ("Click1", "Click2" and "Click3")
2.5 The wefts and clicks added together, attempting to reproduce the speech without the noise. The clicks (corresponding to stop releases in the original sound) do not stream well with the voiced speech.
2.6 All the elements to reconstruct the original.
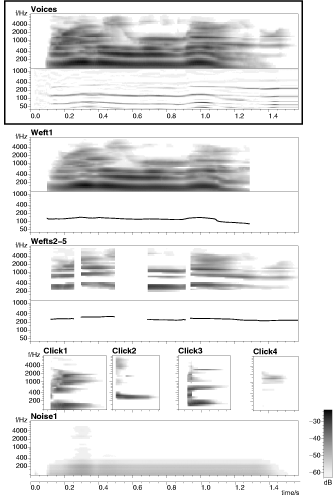
This is the mixture of male and female voices used as an example in Brown's thesis. The analysis objects are illustrated in figure 5.9 (above). The sound examples are:
3.1 The original voice mixture (Brown's "v3n7", 1.6 seconds)
3.2 Background noise cloud ("Noise1")
3.3 Weft corresponding to continuously-voiced male speech ("Weft1")
3.4 Four wefts comprising the voiced female speech ("Wefts2-5")
3.5 Four click elements attached to the speech onsets ("Click1"-"Click4")
3.6 Attempted reconstruction of female voice with both vowels and consonants ("Wefts2-5", "Click1"-"Click4", "Noise1").
3.7 Reconstruction with all elements.
3.8 Brown's example resynthesis of the male voice, for comparison.
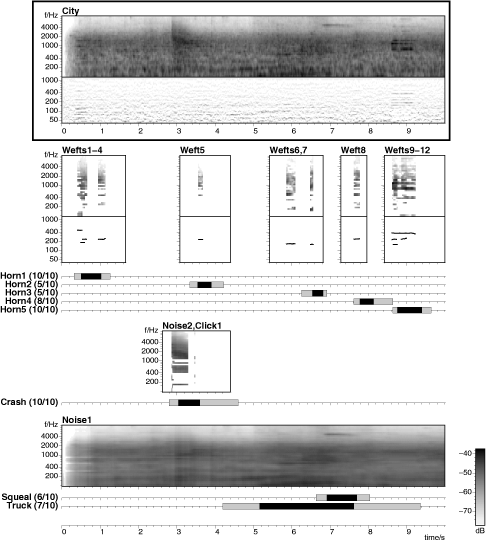
The sound example that motivated the entire thesis, as illustrated in figure 5.17 (above). The sound examples are as follows, where the subjective event name is used when appropriate:
4.1 The original sound (10 seconds)
4.2 Background noise cloud ("Noise1")
4.3 Crash ("Noise2, Click1")
4.4 Horn1, Horn2, Horn3, Horn4, Horn5 ("Wefts1-4", "Weft5", "Wefts6,7", "Weft8", "Wefts9-12")
4.5 Complete reconstruction with all elements
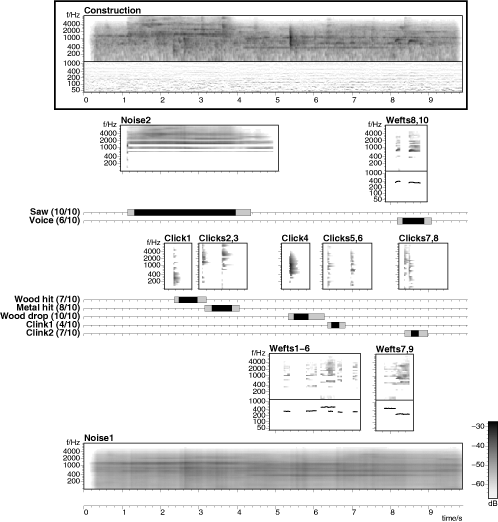
This was the second ambient example used in the subjective listening tests. The elements and the subjective groups are illustrated in figure 5.19 (above).
5.1 Original sound (10 seconds)
5.2 Background ("Noise1")
5.3 Saw ("Noise2")
5.4 Wood hit, Metal hit, Wood drop, Clink1, Clink2 ("Click1", "Clicks2,3", "Click4", "Clicks5,6", "Clicks7,8")
5.5 Voice ("Wefts8,10")
5.6 Extra tonal background ("Wefts1-6", "Wefts7,9")
5.7 Complete resynthesis with all elements
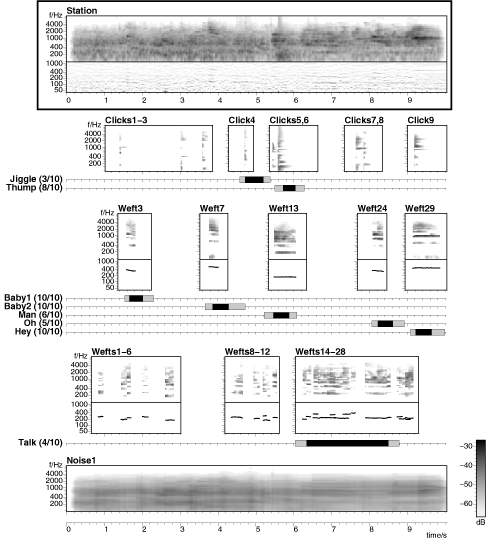
The final ambient example used in the listening tests was this reverberant recording of voices etc. The subjective events and analyzed elements are illustrated in figure 5.21 (above).
6.1 Original sound (10 seconds)
6.2 Background ("Noise1")
6.3 Jiggle, Thump & other click objects ("Click1-3", "Click4", "Clicks5,6", "Clicks7,8", "Click9")
6.4 Baby1, Baby2, Man, Oh, Hey ("Weft3", "Weft7", "Weft13", "Weft24", "Weft29")
6.5 Talk & other background voices ("Wefts1-6", "Wefts8-12", "Wefts14-28")
6.6 Complete resynthesis of all elements.
Back to the Prediction-driven computational auditory scene analysis home page.